Phân tích dữ liệu hành vi bằng ngôn ngữ R
Trong nghiên cứu khoa học xã hội và đời sống hàng ngày chúng ta thường có dữ liệu về hành vi và tâm lý của con người, ví dụ như trắc nghiệm IQ, mô hình 5 nhóm tính cách đặc trưng (Big 5 Personality), net promoter score, và hàng trăm hàng ngàn bài trắc nghiệm hay test khác nhau mà mỗi doanh nghiệp hay tổ chức tự tạo ra nhằm đo lường và đánh giá các đặc tính “vô hình” thuộc về nhân viên như mức độ hạnh phúc, năng lực chuyên môn, khả năng teamwork, vân vân.
Trong thời đại trí tuệ nhân tạo và học máy càng ngày càng phổ biến, các doanh nghiệp thường tập trung vào việc phân tích dữ liệu lớn, tổng hợp hàng trăm nghìn biến (variables/indicators) được thu thập tự động để đưa ra kết luận về một vấn đề gì đấy, mà dữ liệu liên quan đến tâm lý và hành vi truyền thống được thu thập thông qua khảo sát hay phỏng vấn đôi khi bị lu mờ, dù công dụng của loại dữ liệu này, nếu làm đúng, có thể mang lại lợi ích lớn trong việc hiểu thêm về một người nào đấy. Trong bài post này, mình sẽ sử dụng ngôn ngữ R để phân tích một bộ dữ liệu mẫu liên quan đến hành vi bảo mật thông tin của nhân viên một doanh nghiệp lớn ở TPHCM, nơi mình đã tư vấn nâng cấp hệ thống bảo mật thông tin từ năm 2014.
Bài toán phân tích dữ liệu hành vi
Nói sơ qua thì trong phân tích dữ liệu thường làm hai đề bài, một là dự đoán một cái gì đấy, còn hai là tìm patterns hay xu hướng của bộ dữ liệu có trong tay, để làm tăng ý nghĩa của dữ liệu đó. Đầu tiên chúng ta nhìn sơ qua tập dữ liệu. Bộ dữ liệu này gồm 75 indicators (chỉ số) với số lượng mẫu gồm 185 nhân viên (đã được lược bỏ cho mục đích bài post này). Các biến bao gồm demographics như giới tính, tuổi, năm làm việc… và phần lớn các biến còn lại liên quan đến tâm lý và hành vi của nhân viên.
Nói thêm ở đây thì trong nghiên cứu khoa học xã hội liên quan đến tâm lý và hành vi, thường khảo sát có thể sẽ khá dài với cả trăm câu hỏi là bình thường. Lí do là vì cả hành vi lẫn tâm lý, khác với các thước đo có thể thấy được khác như tiền bán hàng hoặc số lượng người theo dõi, thì các biến kể trên đa phần là “vô hình” (Latent), nên mỗi một biến, ví dụ như “suy nghĩ của nhân viên về cách lãnh đạo của sếp” phải được đo lường bằng 5-6 câu hỏi hay indicators như: “Sếp luôn tưởng thưởng hành vi tốt”, “Sếp hay để ý đến các hành động nhỏ của nhân viên”, “Sếp thường làm gương trong công việc”… gom các indicators này lại và phân tích thì mới tạo ra một biến latent để (hi vọng) có thể phản ánh được chân thật khái niệm “vô hình” mà mình đang đo lường.
Tất nhiên thì độ chính xác của việc phản ánh khái niệm “vô hình” đó dựa vào nhiều yếu tố ở các bước khác nhau trong dự án nghiên cứu, từ thiết kế khảo sát/survey, đến thực hiện khảo sát, xử lý dữ liệu tiền phân tích (preprocessing), và áp dụng ĐÚNG kỹ thuật phân tích (ở đây mình nhấn mạnh chữ đúng vì có nhiều dự án áp dụng sai kỹ thuật dẫn đến đưa ra kết quả, dù nhìn số thì rất đẹp, nhưng lại không có giá trị cho việc ra quyết định), và cuối cùng là khâu diễn giả và áp dụng kết quả phân tích.
Quay lại với bộ dữ liệu, 75 biến ở đây nhằm để đo lường các khái niệm như:
- Hành vi bảo mật của sếp trực tiếp
- Hành vi bảo mật của đồng nghiệp
- Biện pháp bảo mật trong doanh nghiệp
- Cảm nhận về trách nhiệm bảo mật của bản thân
- Hành vi bảo mật của bản thân
- …
Kế hoạch phân tích của chúng ta sẽ bao gồm xem xét quan hệ giữa các biến và khái niệm với nhau (ví dụ, biến nào làm gia tăng/giảm giá trị của biến nào), và sau đó có thể mô tả một bức tranh tương đối đầy đủ mà bộ dữ liệu này đang muốn nói lên, để từ đó giúp việc ra quyết định đúng đắn.
Tạo các biến latent
Đầu tiên, chúng ta sẽ tìm cách gom các indicators đơn lẻ lại với nhau để chúng có thể cùng đại diện cho một khái niệm nào đó. Có rất nhiều kỹ thuật khác nhau với lợi/hại riêng, nhưng để tiết kiệm thời gian và trình bày trong bài post này thì hệ phương pháp Partial Least Squares Structural Equation Modeling (PLS-SEM) sẽ được sử dụng. Áp dụng kỹ thuật factor analysis, chúng ta tạo ra 5 biến đại diện cho 5 khái niệm kể trên, bằng cách gom các indicators có liên quan lại với nhau. Khi làm việc này, nghiên cứu viên cần chú trọng vào tính reliability (ổn định) cũng như validity (hiệu lực - bao gồm bên ngoài và bên trong) của từng biến, đảm bảo rằng chúng được tạo nên bởi các indicators thật sự liên quan và có đủ độ khác nhau giữa các biến. Nói qua thì đơn giản, nhưng điều này bao gồm thử đi thử lại các tổ hợp khác nhau và sử dụng các thang đo đúng để đo lường các tính chất nêu trên, cũng như đôi khi phải quay lại về dữ liệu gốc để xem xét thêm nếu kết quả có gì đó bất ổn.
Phân tích quan hệ giữa các biến
Xong bước chuẩn bị và chuyển hoá dữ liệu (từ vài chục indicators đơn lẻ thành 5 biến), mình tiếp tục với việc phân tích mối quan hệ giữa các biến với nhau. Phương pháp PLS-SEM và bootstrapping được sử dụng để đưa ra mô hình cấu trúc cuối cùng mô tả mối quan hệ giữa các biến này. Tất nhiên trước khi đi đến được mô hình cuối cùng vẫn cần phải suy xét và thử nghiệm các tổ hợp mối quan hệ khác nhau, dựa trên nền tảng lý thuyết cũng như tham khảo với doanh nghiệp, để đưa ra mô hình mô tả các mối quan hệ hợp lý nhất. Khi chạy bước phân tích này, một số lưu ý cần phải để tâm đến như các vấn đề tiềm tàng liên quan đến đa cộng tuyến (multicollinearity, nói nôm na là các biến “tranh giành” tác động lên kết quả biến phụ thuộc dẫn đến các tác động thấy được không chính xác), cũng như các mối quan hệ giữa các biến nào được xác định theo tiêu chuẩn xác suất thống kê và vì sao.
Mô hình cấu trúc PLS-SEM cuối được thể hiện bên dưới, với 5 biến chính mô tả hành vi và cảm nhận của nhân viên được trình bày dưới dạng hình lục giác màu xanh, đi kèm với các biến phụ như tuổi, giới tính, năm làm việc, và cấp bậc công việc. Các hình chữ nhật màu xám tượng trưng cho các indicators riêng lẻ đã được gom vào thành các biến chính mà chúng cùng phản ánh.
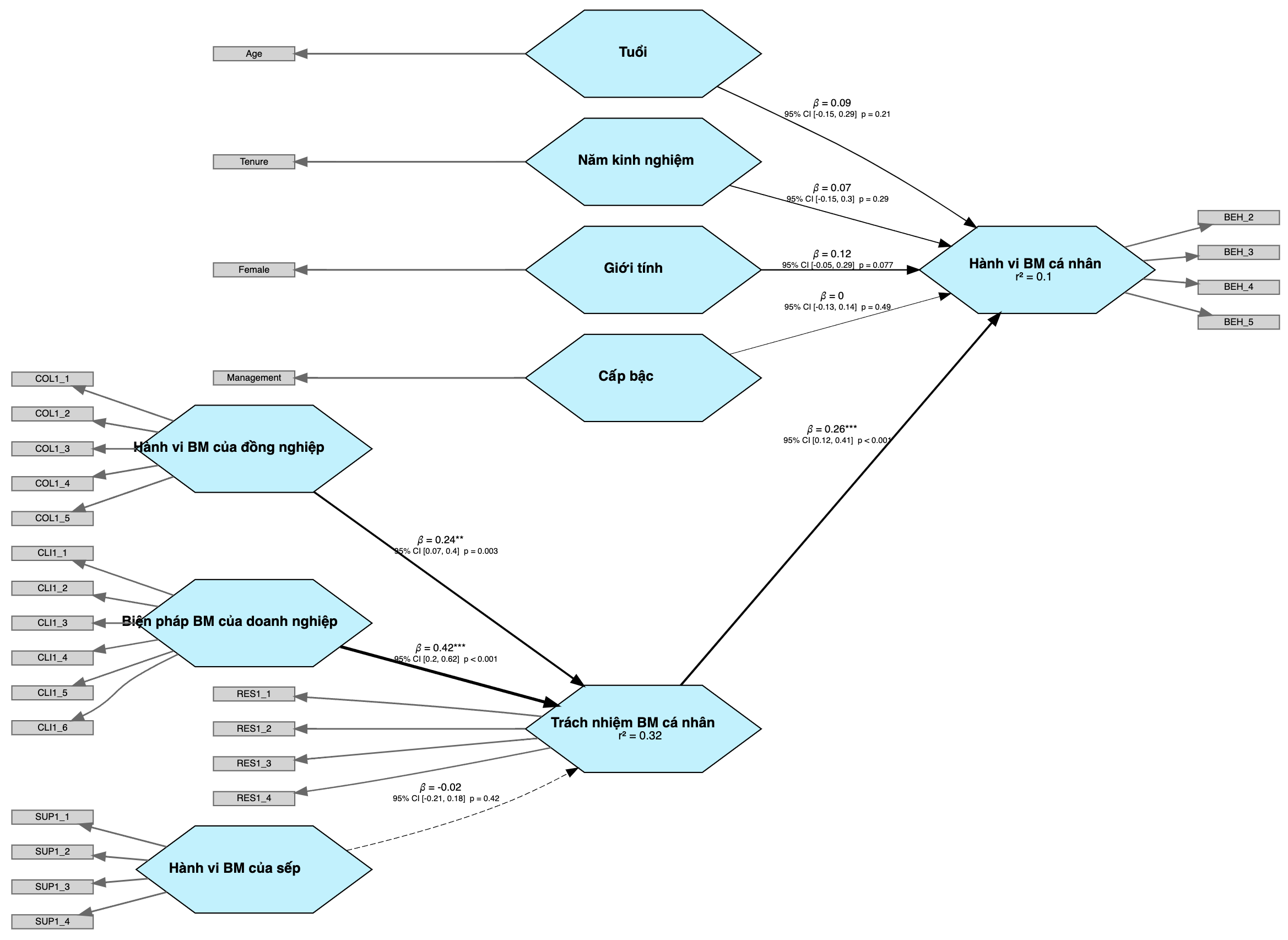
Theo mô hình này, cảm nhận của nhân viên về hành vi bảo mật thông tin của đồng nghiệp và các biện pháp bảo mật được doanh nghiệp triển khai làm tăng cảm nhận về trách nhiệm bảo mật thông tin cá nhân, từ đó làm tăng lên hành vi bảo mật của mỗi nhân viên. Ngoài ra, cảm nhận về hành vi bảo mật của sếp trực tiếp không có tác động lên cảm nhận và trách nhiệm cá nhân, cũng giống như các biến liên quan đến demographics như tuổi và năm kinh nghiệm.
Điều này có thể phản ánh văn hoá riêng của doanh nghiệp ấy, và nhà quản trị nhìn vào kết quả có thể tập trung vào truyền thông nội bộ để làm tăng thêm cảm nhận của nhân viên về công tác bảo mật thông tin trong tổ chức, nhằm làm tăng tinh thần trách nhiệm và hành vi bảo mật của nhân viên. Bên cạnh đó, việc cảm nhận của nhân viên về hành vi bảo mật của đồng nghiệp có tác động nhiều hơn hành vi bảo mật của sếp có thể gợi ý việc thông tin liên quan đến bảo mật thông tin được lan toả nhanh hơn giữa nhân viên với nhân viên, hơn là từ sếp trực tiếp đến nhân viên; có thể nhà quản trị cũng sẽ muốn để ý đến nhận định này.
Hành vi và cảm nhận bảo mật thông tin của nhân viên
Tiếp theo, chúng ta có thể xem xét các cấp bậc về cảm nhận và hành vi bảo mật của nhân viên theo cấp độ từ 1 (thấp nhất) đến 7 (cao nhất), dựa theo thang đo của khảo sát gốc. Thông thường, một số nhà phân tích khi đưa ra một thang đo tổng hợp dựa trên nhiều indicators sẽ cộng tổng và chia trung bình để ra được con số trung bình cộng, hoặc trong trường hợp khác, họ sẽ cộng tổng lại. Ví dụ, thang đo “cách lãnh đạo của sếp” có thể gồm 5 indicators (như ví dụ nêu ở đầu bài viết) được đánh giá bởi một nhân viên bất kì có giá trị: 3, 4, 4, 5, 3, thì điểm trung bình phản ánh cảm nhận của nhân viên này là: \(\frac{\left(3+4+4+5+3\right)}{5}\) là 3.8 trên 5 điểm tối đa.
Tuy kết quả này có thể sử dụng được ở một chừng mực nào đó, vấn đề tính toán lớn nhất của các phương pháp này chính là việc xem các indicators có “trọng lượng” ngang nhau khi cộng chúng lại và chia trung bình. Phương án áp trọng số cho từng indicator được đưa ra nhằm giải quyết vấn đề nói trên, tuy nhiên cách này cũng có vấn đề trong chính việc đưa ra trọng số ấy, liệu rằng các trọng số được áp dụng dựa trên cơ sở gì (ví dụ, vì sao indicator A lại có trọng số 0.7 so với indicator B có trọng số 1.5), và các trọng số này có chính xác hay không.
Nếu áp dụng phương pháp phân tích dữ liệu phù hợp, chúng ta có thể loại bỏ được nhiều nhất có thể các thiên kiến (bias) chủ quan trong việc đo lường, và mục tiêu bây giờ là mô tả được dữ liệu theo cách chân thật nhất có thể - bằng cách đo lường độ khớp (goodness of fit) của kết quả chúng ta lấy được từ phân tích so với đặc tính thống kê của bộ dữ liệu. Hình bên dưới thể hiện histogram của 5 biến chính trong mô hình PLS-SEM, với trục ngang trình bày thang đo với cấp độ từ 1 đến 7, và trục dọc thể hiện số lượng nhân viên thuộc về từng cấp độ trong thang đo. Các giá trị ở đây có độ chính xác cao, vì chúng được tính toán sử dụng phương pháp áp trọng số, nhưng các trọng số được tính riêng cho từng indicator dựa trên phương pháp phân tích dữ liệu với tiêu chí khớp nhắc đến ở trên.
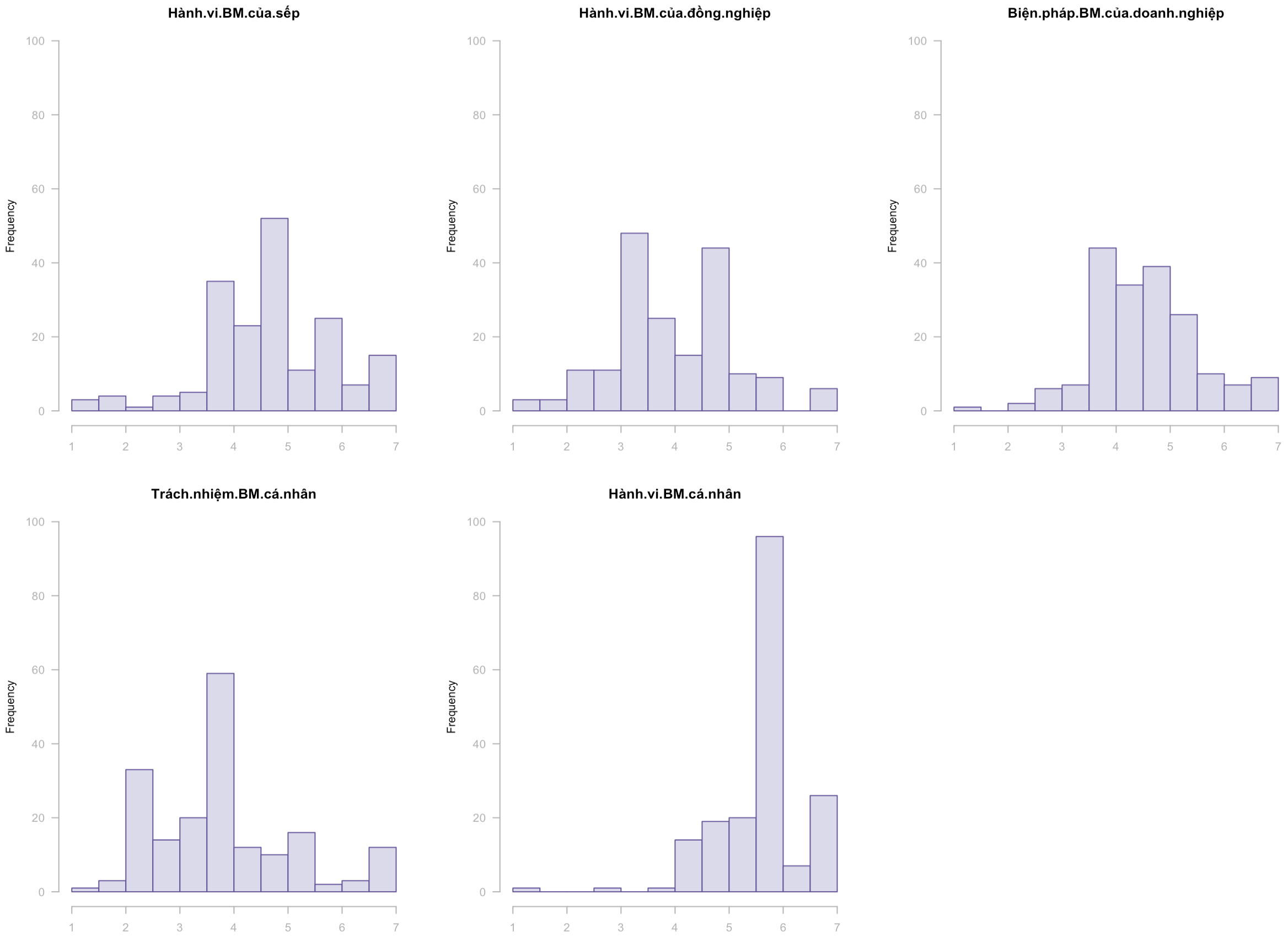
Theo như trong hình, các cảm nhận về bảo mật thông tin của nhân viên trong tổ chức đang ở mức trung bình-khá, với một số cảm nhận như về hành vi bảo mật của sếp hay đồng nghiệp, chúng ta có thể thấy chia làm hai nhóm rõ rệt - thấp (từ 4 trở xuống) và trung bình-cao (từ 4 trở lên). Cảm nhận về biện pháp bảo mật thông tin của doanh nghiệp tạo ra histogram với số lượng nhân viên trải đều ở các cấp độ từ thấp đến cao. Kết quả này hợp lý vì các biện pháp bảo mật trong toàn doanh nghiệp thì sẽ được để ý đồng đều hơn so với hành vi của đồng nghiệp hay sếp trực tiếp sẽ bị giới hạn trong từng phòng ban. Dựa theo kết quả phân tích này, một lần nữa nhà quản trị có thể hiểu về cảm nhận và hành vi bảo mật của nhân viên trong tổ chức, và đưa ra các biện pháp cải thiện phù hợp.
Phân nhóm nhân viên dựa trên cảm nhận về bảo mật thông tin
Tiếp tục với mục tiêu mô tả tập dữ liệu, từ các điểm số về cảm nhận và hành vi bảo mật ở trên, chúng ta có thể dùng chúng để phân nhóm nhân viên dựa trên điểm của mỗi cá nhân. Có nhiều phương pháp phân nhóm, nhưng ở đây mình sẽ sử dụng phương pháp latent profile analysis (LPA) vì tính tương thích với dữ liệu dạng điểm số. Phương pháp LPA gợi ý rằng với 3 biến liên quan đến cảm nhận của nhân viên, chúng ta có thể có được 3 nhóm nhân viên khác nhau như trong hình dưới đây.
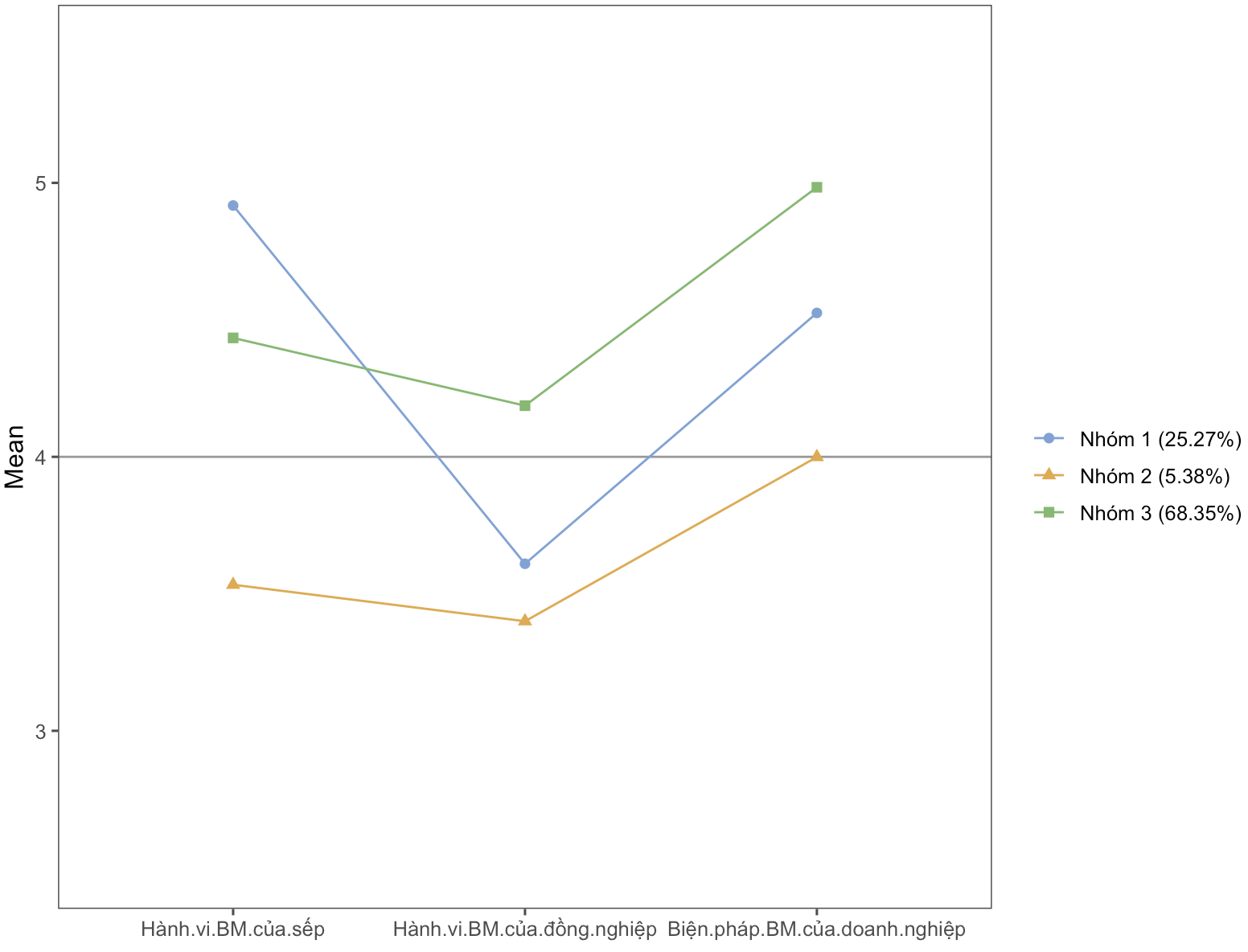
Cụ thể, nhóm 1 (chiếm 25.27% của tập dữ liệu) có điểm số liên quan đến cảm nhận về hành vi bảo mật của sếp trực tiếp và về các biện pháp bảo mật của doanh nghiệp trên mức trung bình, còn cảm nhận về hành vi bảo mật của đồng nghiệp lại ở dưới mức trung bình (điểm số 4). Nhóm 3 là nhóm phổ biến, chiếm 68.35%, có điểm số liên quan tới 3 loại cảm nhận đều trên mức trung bình. Nhóm cuối cùng và thiểu số là nhóm 2, chiếm 5.38% của tập dữ liệu, có 3 loại cảm nhận đều ở dưới trung bình. Theo góc nhìn của nhà quản trị, nhóm số 2 có thể là nhóm cần đặc biệt chú ý nhất.
Dữ liệu phân loại các nhóm nhân viên có thể dễ dàng được sử dụng cho các phân tích tiếp theo, ví dụ như so sánh với các đặc điểm demographics của nhân viên. Lấy ví dụ như chúng ta có thể xem các nhóm nhân viên kể trên bao gồm nhân viên thuộc các nhóm với số năm làm việc tại doanh nghiệp như hình sau.
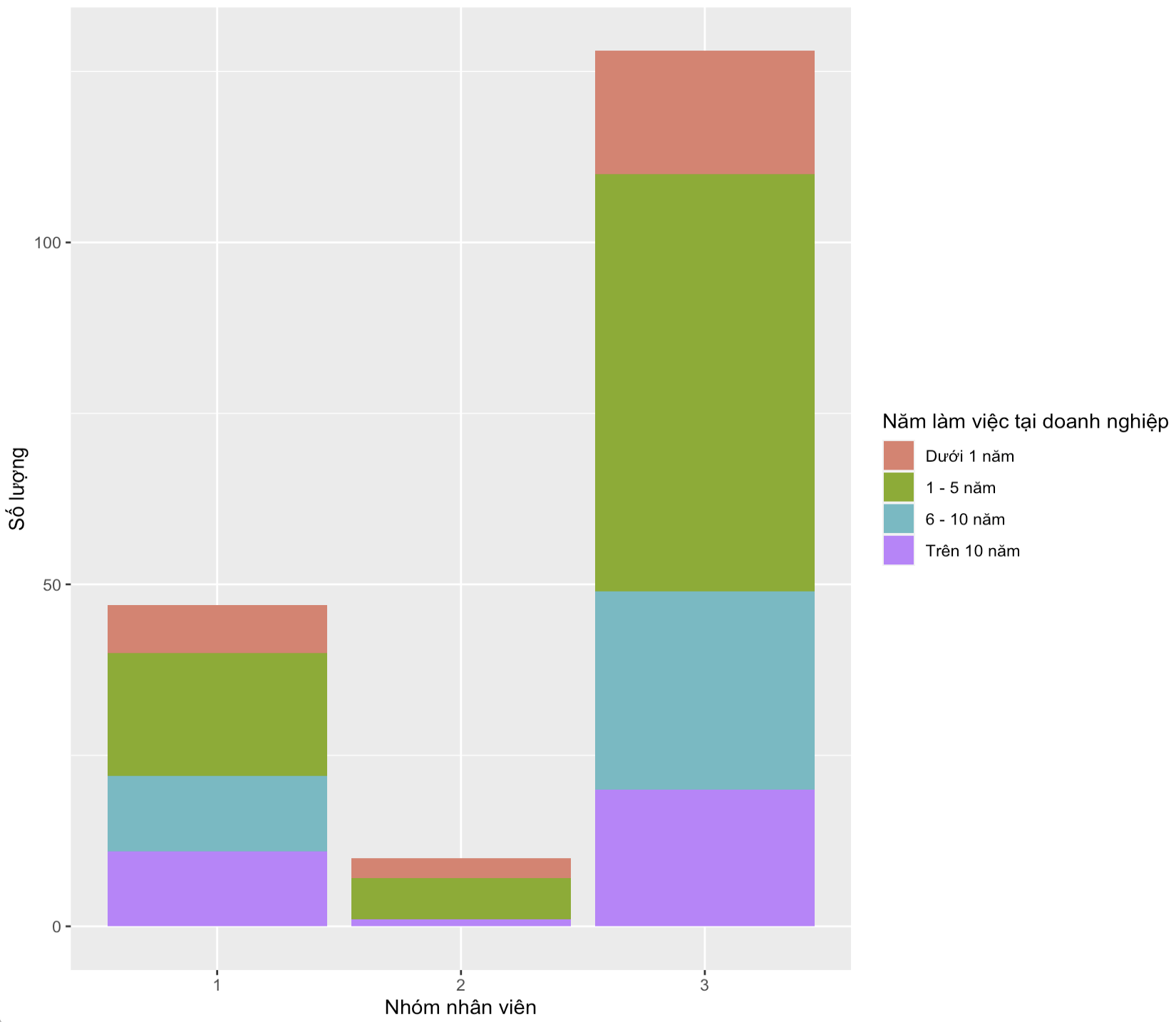
Bằng việc so sánh này, chúng ta thấy được thêm Nhóm 2 (nhóm cần được chú ý vì điểm số của 3 loại cảm nhận đều dưới mức trung bình) bao gồm đa số các nhân viên có dưới 5 năm làm việc tại doanh nghiệp hiện tại. Kết hợp với các đặc điểm khác như giới tính, tuổi tác, trụ sở hay phòng ban… nhà quản trị có thể lựa chọn biện pháp truyền thông nội bộ hoặc training phù hợp để hỗ trợ cho nhóm cần lưu ý này.
Kết luận
Thông qua bài viết này, mình hi vọng có thể cho người đọc một bức tranh mô tả chung về tác dụng của phân tích dữ liệu hành vi của nhân viên trong việc giúp nhà quản trị hiểu rõ hơn về những thứ “vô hình” trong tổ chức, ví dụ như cảm nhận và hành vi bảo mật thông tin của nhân viên, và từ đó có thể suy nghĩ và đưa ra các giải pháp phù hợp. Tất nhiên, bài viết không mang tính kỹ thuật và không thể hiện hết các lựa chọn của nghiên cứu viên trong suốt toàn bộ quá trình phân tích. Ngoài ra, trong phân tích dữ liệu còn có một câu nói nổi tiếng: “Garbage in, garbage out”, hay dịch thoáng ra là nếu dữ liệu đầu vào là rác, thì chúng ta có thể mong đợi kết quả rác tương tự. Như đã đề cập đến đâu đó trong bài viết này, thì việc thiết kế công cụ thu thập dữ liệu hành vi (như khảo sát, bảng phỏng vấn…) cũng quan trọng không kém, và cần có sự tham khảo kĩ lưỡng cũng như tính chuyên môn cao.
Enjoy Reading This Article?
Here are some more articles you might like to read next: