Streamlit for data app
For data scientists and machine learning engineers who use Python, streamlit provides an easy-to-use and intuitive framework for creating data apps. To start creating data apps with streamlit, first install it:
pip install streamlit
For demonstration, let’s create an app to display the ABDC journal quality list. First, we import the necessary packages:
import pandas as pd
import numpy as np
import requests
import streamlit as st
With streamlit imported, we can start writing the title of our data app:
st.title("Journal Ranking")
In the terminal, we run the Python script by typing:
streamlit run [filename]
A browser will be opened and it shows our data app with the title “Journal Ranking” as we specified above.
The ABDC journal quality list is an Excel spreadsheet file that contains the ranks of multidisciplinary academic journals. Since it is a spreadsheet, we can download and store the data as a pandas dataframe:
ABDC = "https://abdc.edu.au/wp-content/uploads/2020/04/abdc_jql_2019_0612-1.1.xlsx"
raw_abdc = download_data(ABDC)
To display this dataframe on our data app, there are multiple ways for doing this. Conveniently, streamlit provides the “magic commands” that allow us to write information to our app with a few keypresses. In this case, we can write the dataframe to our data app by:
st.dataframe(raw_abdc)
# Or by using magic command
raw_abdc
Another convenient feature that streamlit offers is caching, which allows performing expensive operations quickly. We can use caching to support loading the ABDC data set from the URL specified above. First, we create a function to load the data. Second, we add the @st.cache decorator before the load function:
# Download ABDC list
@st.cache
def download_data(data_url):
return(pd.read_excel(data_url, header=8))
# ABDC data
st.header("ABDC List")
raw_abdc = download_data(ABDC)
raw_abdc
By using the @st.cache decorator, you should notice that the data set is loaded much faster than before.
The current limitation of streamlit’s dataframe is that it does not have the filtering feature. So, let’s create a function to filter the ABDC journal ranking list based on two important criteria: 1) journals’ ranks, and 2) publishers.
ABDC journal ranking list consists of five categories: A** (i.e., elite journals), A*, A, B, and C. On the other hand, the list of publishers can be quite extensive.
With streamlit, we can add two dropdown lists that allow the users to select the ranks and the publishers to show only the journals that match these criteria. Since there are two filters (i.e., journal ranks and publishers) and multiple criteria for each filter, we can use a dictionary to store these values as pairs of filter and criteria:
st.subheader("Filter:")
# Get the list of unique publishers
publishers_list = raw_abdc["Publisher"].unique()
filter_values = {
"2019 Rating": st.multiselect("Select journal ranks:", ("A**","A*", "A", "B", "C")),
"Publisher": st.multiselect("Select publishers:", publishers_list)
}
Here, we use st.multiselect to create the dropdown lists that contain the values that can be selected by the users to filter the journals. Now, we can use the dictionary filter_values to dynamically create queries for subsetting pandas dataframes:
final_query = ""
for feature_name, criteria in filter_values.items():
if len(criteria) > 0:
query = "`{}` in {}".format(feature_name, criteria)
final_query = final_query + " & " + query
else:
pass
Let’s output the query to check it:
st.write("Query string:", final_query[2:])
Finally, we can use this query to subset the ABDC journal ranking list dynamically on our streamlit app:
if final_query[2:] != "":
filtered_data = raw_abdc.query(final_query[2:])
else:
st.stop()
st.warning("Please select some filter criteria first.")
filtered_data
Note here that we use st.stop() and st.warning() to control the flow of our data app. If the query is empty, i.e., the user do not specify any filters, then the app is stopped and a warning message is shown until the users choose at least one filter.
While creating this simple app, I also note a common issue when using df.query to subset pandas dataframes that contain column names with spaces e.g., the “2019 Ranking” column in the ABDC data set.
The solution here is to use the backtick ` ` to wrap the column name. Another solution is to replace the spaces in the column names by _, however this solution is not ideal since it alters the original column names.
Here is a screenshot of the app:
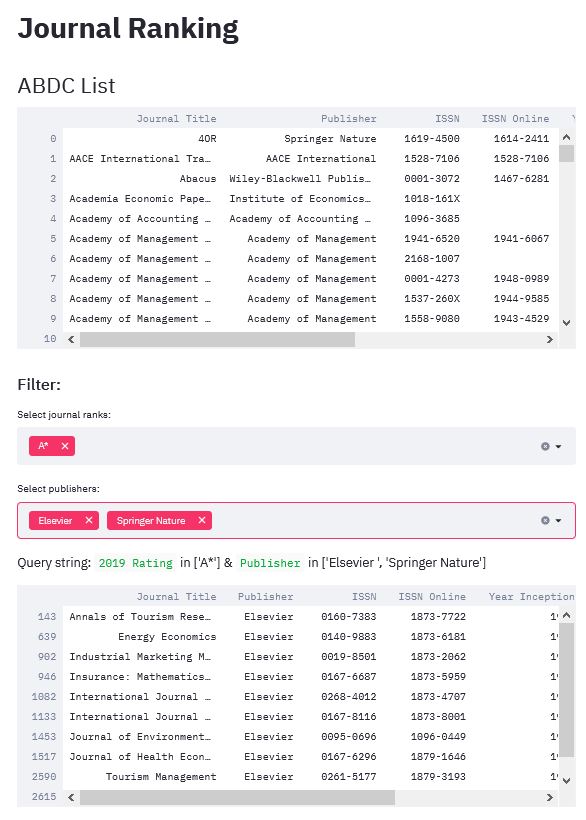
The full code for this simple streamlit app is as follows:
import pandas as pd
import numpy as np
import requests
import streamlit as st
ABDC = "https://abdc.edu.au/wp-content/uploads/2020/04/abdc_jql_2019_0612-1.1.xlsx"
# Header
st.title("Journal Ranking")
# Download ABDC list
@st.cache
def download_data(data_url):
return(pd.read_excel(data_url, header=8))
# ABDC
st.header("ABDC List")
raw_abdc = download_data(ABDC)
raw_abdc
st.subheader("Filter:")
publishers_list = raw_abdc["Publisher"].unique()
filter_values = {
"2019 Rating": st.multiselect("Select journal ranks:", ("A**","A*", "A", "B", "C")),
"Publisher": st.multiselect("Select publishers:", publishers_list)
}
final_query = ""
for feature_name, criteria in filter_values.items():
if len(criteria) > 0:
# query = " ".join(feature_name, criteria)
query = '`{}` in {}'.format(feature_name, criteria)
final_query = final_query + " & " + query
else:
pass
st.write("Query string:", final_query[2:])
if final_query[2:] != "":
filtered_data = raw_abdc.query(final_query[2:])
else:
st.stop()
st.warning("Please select some filter criteria first.")
filtered_data
Enjoy Reading This Article?
Here are some more articles you might like to read next: