Analyzing Apple Health data
As I thought that I should care more about my health, I bought a treadmill and after two months of regular running and walking on the treadmill, I lost 7 kgs. I used Apple Watch (Series 3 - not very accurate in fitness tracking based on what I have read) to keep track of my workouts and the Xiaomi Smart Scale 2 for measuring weights and other physical metrics, and all these data are synced and stored in the Apple’s Health app on iPhone. Although the Health app provides useful analyses and visualizations of these data, we can export and analyze the data by using Python as well.
To export the data, simply go to your personal profile in the Health app and select “Export all data”. There are different ways to export the data, but I found sending the data to my email address to be the easiest way. Then, we can download the sent file and unzip it, and inside the unzipped folder, we will analyze the ‘export.xml’ file.
At first glance, we would notice that each data point is recorded as an element that has the <Record> tag. Within this tag, there are multiple attributes such as type, sourceName, startDate, endDate, value, and so on.
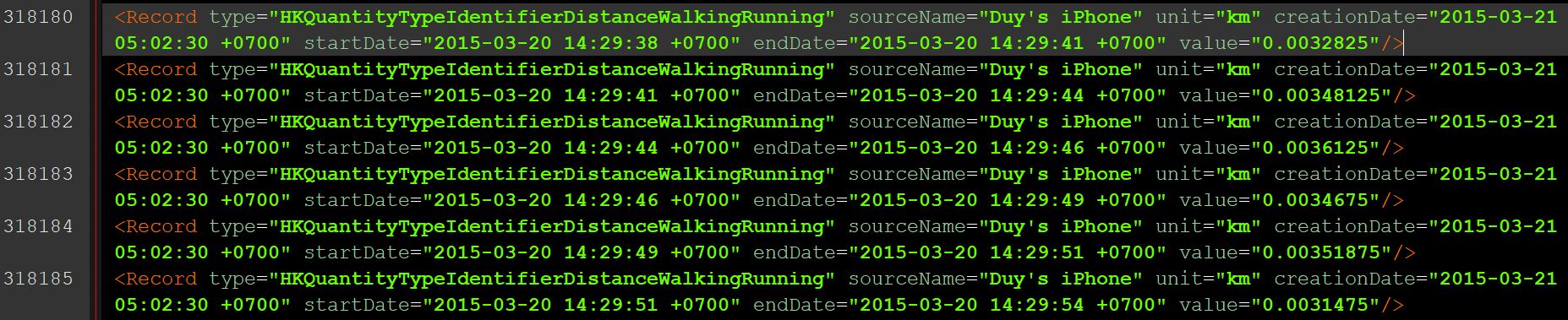
To import and load the XML data:
import lxml.etree as ET
import pandas as pd
tree = ET.parse("export.xml")
root = tree.getroot()
attribute = []
endDate = []
value = []
sourceName = []
for element in root.xpath("//Record[(@type='HKQuantityTypeIdentifierActiveEnergyBurned' or \
@type='HKQuantityTypeIdentifierStepCount') and \
contains(@sourceName, 'Watch')]"):
attribute.append(element.get('type'))
endDate.append(element.get('endDate'))
value.append(element.get('value'))
exercise = pd.DataFrame({'attribute': attribute, 'endDate': endDate, 'value':value})
exercise.value = pd.to_numeric(exercise.value)
exercise.endDate = pd.to_datetime(exercise.endDate)
exercise.endDate = exercise.endDate.dt.date
exercise
Here I used xpath to get all elements with the attributes that contained data about “Active Energy Burned” and “Step Count”, and especially that the data were recorded by my Apple Watch. Each element’s values were appended to the lists which were used to construct a DataFrame called “exercise”.
Next, I created a pivot table to summarize these data. Specifically, I summed the data to calculate the total amounts of active energy burned and step count for each day. This reduced 190,872 rows of data to only 268 rows (i.e., 268 days). Because we sum the data, earlier the “value” column was converted to numeric.
exercise_pivot = exercise.pivot_table(values='value', columns='attribute', index='endDate', aggfunc='sum').to_records()
exercise_pivot = pd.DataFrame(exercise_pivot)
exercise_pivot.columns = ['endDate', 'ActiveEnergyBurned', 'StepCount']
exercise_pivot.endDate = pd.to_datetime(exercise_pivot.endDate)
exercise_pivot
Let’s use the same code to extract data about body mass. In the snippet below, I wanted to get the elements which contained data that were recorded by Mi Fit (the source name of the Xiaomi smart scale) and their unit was measured in “kg”.
attribute = []
endDate = []
value = []
for element in root.xpath("//Record[@sourceName='Mi Fit' and @unit='kg']"):
attribute.append(element.get('type'))
endDate.append(element.get('endDate'))
value.append(element.get('value'))
bodyMass = pd.DataFrame({'attribute': attribute, 'endDate': endDate, 'value':value})
bodyMass.value = pd.to_numeric(bodyMass.value)
bodyMass.endDate = pd.to_datetime(bodyMass.endDate)
bodyMass.endDate = bodyMass.endDate.dt.date
bodyMass
There were some duplicates in this bodyMass DataFrame, since I removed the time from the endDate column to keep only the date, and apparently on some days I measured my weight multiple times and received the same results. So, I removed the duplicates:
bodyMass.drop_duplicates(keep='last', inplace=True)
bodyMass
And then proceeded to creating the pivot table, but this time I calculated the average body mass per day instead of doing the summation as above:
bodyMass_pivot = bodyMass.pivot_table(values='value', columns='attribute', index='endDate', aggfunc='mean').to_records()
bodyMass_pivot = pd.DataFrame(bodyMass_pivot)
bodyMass_pivot.columns = ['endDate', 'BodyMass', 'LeanBodyMass']
bodyMass_pivot.endDate = pd.to_datetime(bodyMass_pivot.endDate)
bodyMass_pivot
Now we merge the two DataFrames, “exercise” and “bodyMass”:
combined_df = pd.merge(exercise_pivot, bodyMass_pivot, how='left', on='endDate')
combined_df
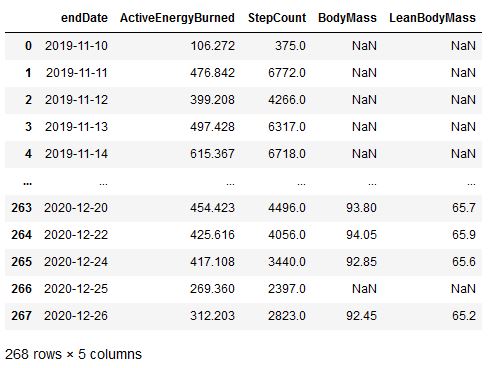
Although I have been wearing the Apple Watch since 2019, I just recently started exercising and measuring my weights with the Xiaomi smart scale since October 2020, so there were missing data (NaN) in my merged DataFrame. We can drop these missing data:
combined_df.dropna(inplace=True)
Now we have a consolidated data set of only 33 data points which represent the 33 days that I used the smart scale to measure my weights.
We can use the package seaborn to visualize the data, for example, about active energy burned:
import seaborn as sns
import matplotlib.pyplot as plt
f = plt.figure(figsize=(12, 6))
sns.set_style('whitegrid')
sns.set_context('paper', font_scale=1.5)
sns.lineplot(
data=combined_df['ActiveEnergyBurned']
);
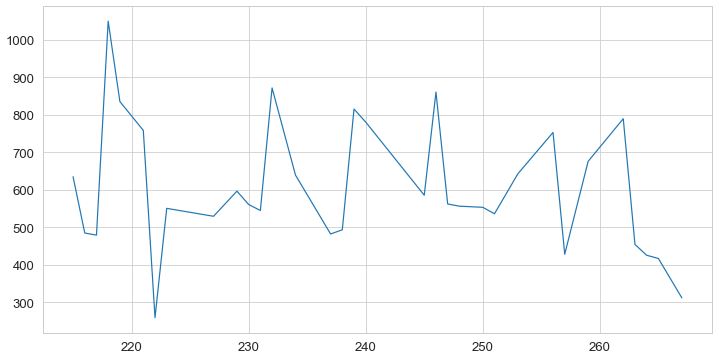
Or if we want to draw multiple lines within the same line chart:
combined_df_melted = pd.melt(combined_df, id_vars='endDate')
f = plt.figure(figsize=(12, 6))
sns.set_style('whitegrid')
sns.set_context('paper', font_scale=1.5)
sns.lineplot(
data=combined_df_melted.query("variable == ['ActiveEnergyBurned','StepCount']"),
x='endDate', y='value', hue='variable'
);
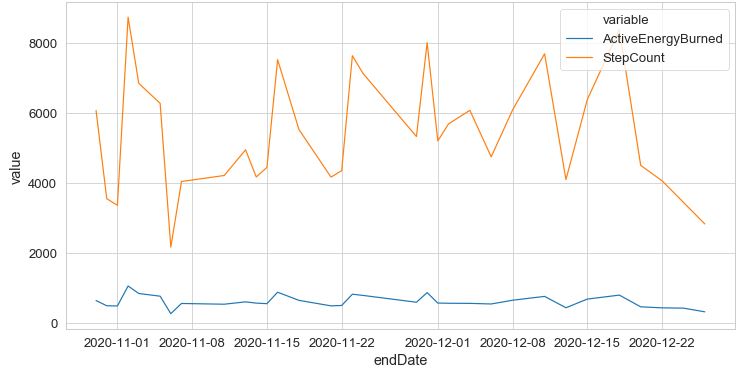
So in this short and simple post, we have performed the following tasks in Python:
- Import XML file and extract data by using xpath
- Perform some data cleaning and processing
- Visualize the data with the seaborn package
There are many more interesting things that we can find from this data set, and I hope you will enjoy analyzing your own Apple’s Health data as well!
Enjoy Reading This Article?
Here are some more articles you might like to read next: